Search Process Visualization
We visualize how search agents explore a knowledge graph under sequential vs. parallel search. The videos highlight the structural difference between linearized exploration and fan-out evidence gathering, which is critical for deep research tasks requiring broad coverage and reliable synthesis.
Sequential Search
SequentialParallel Search
Parallel1) Search Breadth
Traverses the graph one node at a time, linearizing inherently parallel fan-out structures.
Activates relevant nodes simultaneously, preserving the natural fan-out of the knowledge graph.
2) Context Representation
Accumulates evidence as a long, ordered text trace, increasing noise and risking partial visibility.
Maintains evidence as a structured set of nodes and relations, compactly preserving global context.
3) Comparison Timing
Defers comparison until late, making decisions fragile and dependent on recall of earlier results.
Enables immediate global comparison once attributes are retrieved, turning comparison into a direct selection step.
4) Termination Reliability
Prone to premature termination after partial exploration due to step limits or heuristic stopping.
Enables complete candidate coverage before selection, making termination conditions explicit and reliable.
Abstract
Large reasoning models (LRMs) combined with retrieval-augmented generation (RAG) have enabled deep research agents capable of multi-step reasoning with external knowledge retrieval. However, previous methods that extend reasoning with single-query search steps struggle to scale to complex tasks demanding broad document exploration. Meanwhile, approaches that generate multiple independent queries simultaneously may limit deeper, sequential reasoning.
To address these limitations, we propose HybridDeepSearcher that dynamically integrates parallel and sequential search strategies to enable effective search scaling. To support training, we introduce HDS-QA, a novel dataset that seamlessly integrates broad parallel search with sequential search reasoning, providing answer trajectories in the form of reasoning-query-retrieval loops with parallel sub-queries.
Across all five benchmarks, our approach significantly outperforms the state-of-the-art, improving F1 scores by +15.9 on FanOutQA and +11.5 on a subset of BrowseComp. Further analysis reveals that HybridDeepSearcher effectively scales performance with additional test-time search resources and demonstrates robustness on questions requiring more evidence, achieving higher evidence coverage.
Why Hybrid Search for Deep Research?
Deep research is not a single fact lookup; successful agents must cover many candidates, retrieve comparable evidence, and synthesize globally. This creates a natural fan-out → fan-in pattern: expand to gather evidence broadly, then aggregate and select.
Parallel retrieval for coverage
Parallel search activates many candidate nodes (documents/entities/attributes) at once, preventing narrow exploration and improving evidence coverage early in the process.
Sequential reasoning for depth
After broad retrieval, sequential reasoning integrates results to refine constraints, resolve conflicts, and complete multi-hop synthesis.
Key Findings
- State-of-the-art across all benchmarks: HybridDeepSearcher significantly outperforms all baselines across all five benchmarks, doubling model judge accuracy on FanOutQA that requires 7 pieces of evidence per question on average.
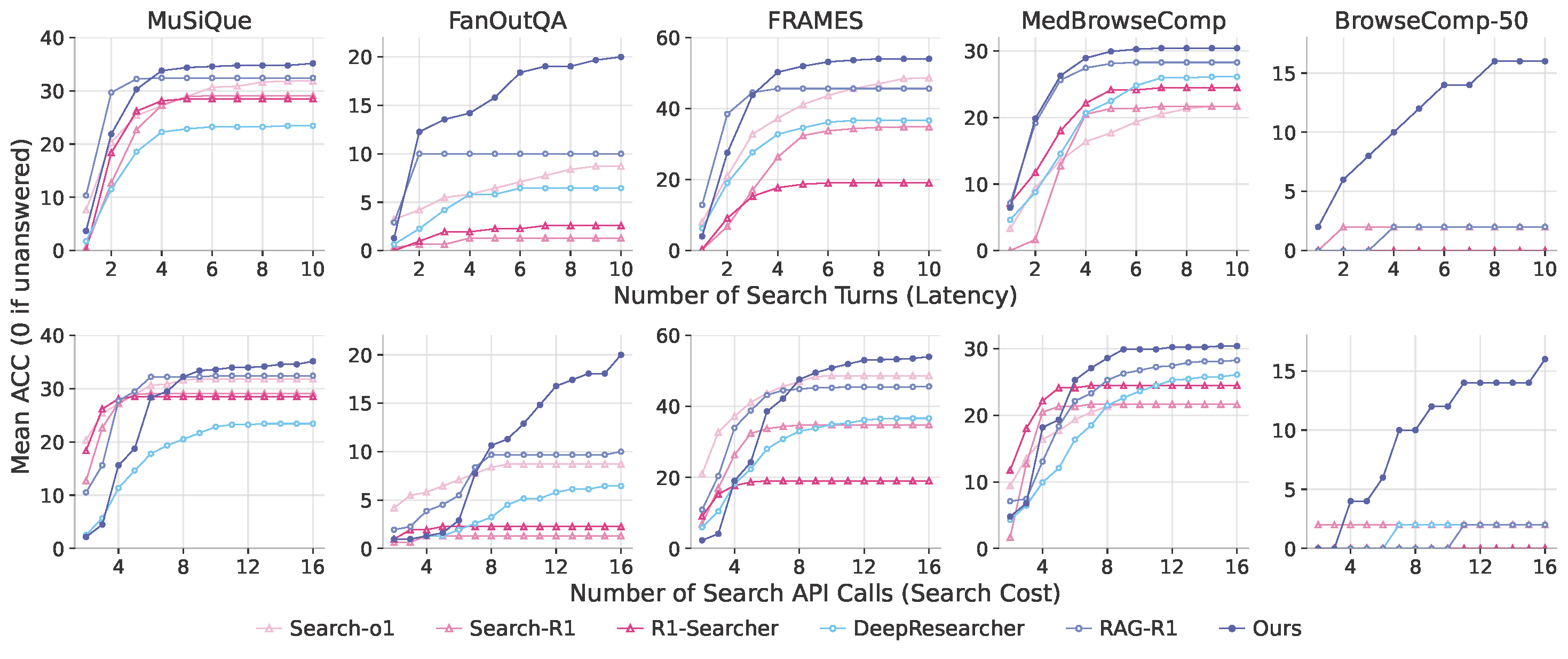
- Effective search scaling: Our model consistently improves as search turns or calls increase, collecting more evidence (+7 coverage gain on FanOutQA and FRAMES), while other baselines remain stagnant or even fail to improve on BrowseComp.
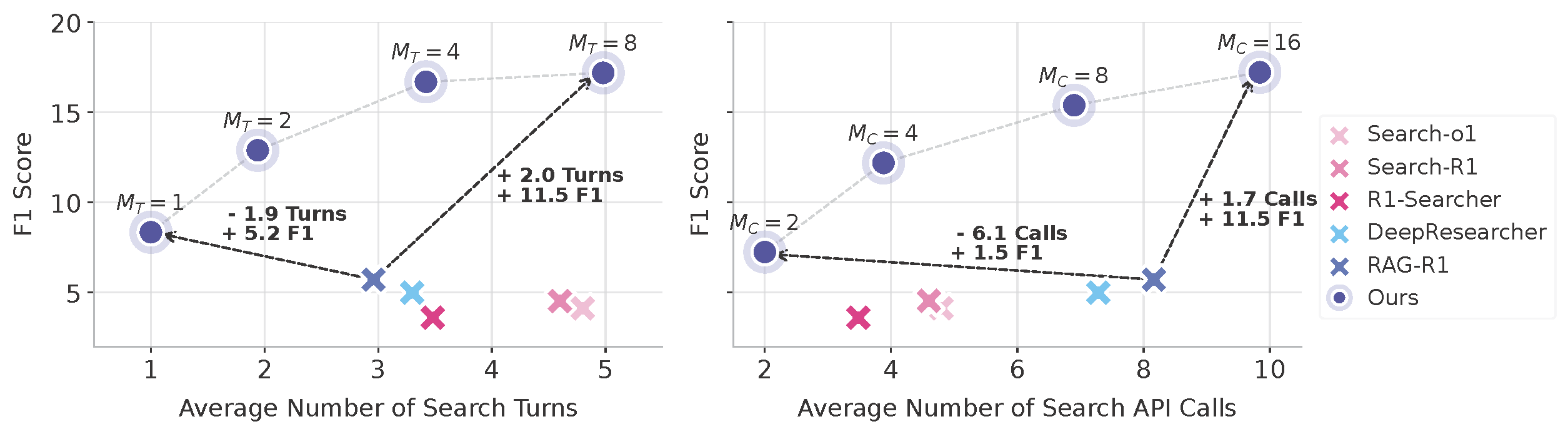
- Strong efficiency: It achieves comparable performance with fewer turns, showing the highest efficiency (AUC) among all baselines.
- Robustness to evidence complexity: As the number of required evidence increases, our model shows minimal performance loss, while others suffer significant decline—resulting in performance gaps from 2 points (two-document questions) to 9 points (four-document questions) on MuSiQue.
Method: HDS-QA Dataset
We introduce HDS-QA, a supervised dataset designed to teach models how to integrate parallel and sequential search. HDS-QA is the first dataset that (i) supports beyond two parallel sub-queries to increase the breadth of parallel search, and (ii) explicitly incorporates broad parallel search results into sequential search reasoning.

Question Generation. Our pipeline consists of four steps (using Qwen3-32B throughout):
- Entity extraction & related question collection: Starting from a single-hop seed question (NQ), we extract a central entity and collect diverse related questions via Google's People Also Ask, filtering duplicates by document overlap.
- Entity characteristic summarization: For each related question, we summarize retrieved documents into 3–5 concise statements capturing key characteristics of the entity.
- Parallel-hop question formulation: We compose a parallel-hop question that implicitly references the entity, encouraging multiple independent searches without explicitly naming closely associated entities.
- Integration into hybrid-hop questions: We replace the entity in the seed question with the parallel-hop question, introducing an additional sequential hop and verifying that the resulting question cannot be answered with a single retrieval step.
Answer-Trajectory Generation. We create answer trajectories through iterative loops of reasoning, querying, and retrieval. We retain trajectories only if the final answer is correct; trajectories may include intermediate mistakes as long as they recover, providing supervision for error correction. To encourage diversity, we run inference four times per question and retain all successful trajectories (2,111 trajectories from 7,948 attempts; pass@4 = 38.9%).
Main Results
We evaluate on five QA benchmarks covering both sequential and parallel search reasoning: MuSiQue, FanOutQA, FRAMES, MedBrowseComp, and BrowseComp-50.
| Method | MuSiQue F1 / Acc |
FanOutQA F1 / Acc |
FRAMES F1 / Acc |
MedBrowseComp F1 / Acc |
BrowseComp-50 F1 / Acc |
|---|---|---|---|---|---|
| Naïve Gen | 12.8 / 16.4 | 10.9 / 3.2 | 14.0 / 17.5 | 8.0 / 11.9 | 0.0 / 0.0 |
| Standard RAG | 15.8 / 24.8 | 20.6 / 5.6 | 21.9 / 30.9 | 11.3 / 16.3 | 1.8 / 0.0 |
| Search-o1 | 23.4 / 31.8 | 26.7 / 8.7 | 34.2 / 48.6 | 12.9 / 21.6 | 4.1 / 2.0 |
| Search-R1 | 26.6 / 29.1 | 10.1 / 1.2 | 27.3 / 34.8 | 18.8 / 21.6 | 4.5 / 2.0 |
| DeepResearcher | 21.7 / 23.4 | 26.4 / 6.5 | 28.5 / 36.6 | 14.7 / 26.1 | 5.0 / 2.0 |
| RAG-R1 | 29.7 / 32.4 | 28.2 / 10.0 | 35.8 / 45.6 | 19.2 / 28.2 | 5.7 / 2.0 |
| HybridDeepSearcher | 31.2 / 35.1 | 44.1 / 20.0 | 39.1 / 54.0 | 19.8 / 30.4 | 17.2 / 16.0 |
Best results in each column are marked in bold. HybridDeepSearcher achieves the highest F1 and Acc scores across all five benchmarks.
Efficiency: Effectiveness–Latency Trade-off
Across all benchmarks, HybridDeepSearcher achieves the highest efficiency (AUC). While RAG-R1 often consumes fewer turns, it tends to plateau after ~2-3 turns and fails to leverage additional search budget, resulting in a lower AUC despite lower latency.
Evidence Coverage
We examine search capability by measuring whether gold evidence documents are retrieved using queries generated by models.
| Method | MuSiQue | FanOutQA | FRAMES |
|---|---|---|---|
| Search-o1 | 33.4 | 38.3 | 44.8 |
| DeepResearcher | 38.8 | 49.9 | 49.0 |
| RAG-R1 | 35.9 | 53.2 | 48.0 |
| HybridDeepSearcher | 40.7 | 61.0 | 55.8 |
Evidence coverage rate (%). HybridDeepSearcher achieves the highest coverage across all benchmarks.
Citation
@inproceedings{
ko2026hybrid,
title={Hybrid Deep Searcher: Scalable Parallel and Sequential Search Reasoning},
author={Dayoon Ko and Jihyuk Kim and Haeju Park and Sohyeon Kim and Dahyun Lee and Yongrae Jo and Gunhee Kim and Moontae Lee and Kyungjae Lee},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=rXpTZyucal}
}
}